



eBPF Documentation
eBPF est une technologie révolutionnaire issue du noyau Linux qui peut exécuter des programmes dans un environnement confiné, mais avec les privilèges du noyau du système d'exploitation. eBPF est utilisé pour étendre de façon sûre et efficace les capacités du noyau, sans qu'il soit nécessaire de modifier le code source du noyau ou de charger des modules.
Depuis toujours, le système d'exploitation est l’endroit idéal pour implémenter des solutions d'observabilité, de sécurité et de mise en réseau, en raison de la situation privilégiée du noyau pour superviser et contrôler l'ensemble du système. Évidemment, le noyau d’un système d'exploitation est difficile à faire évoluer en raison de son rôle central et de ses exigences élevées en matière de stabilité et de sécurité. L’innovation au cœur du système d’exploitation suit donc un rythme plus lent que celui des applications utilisateurs.
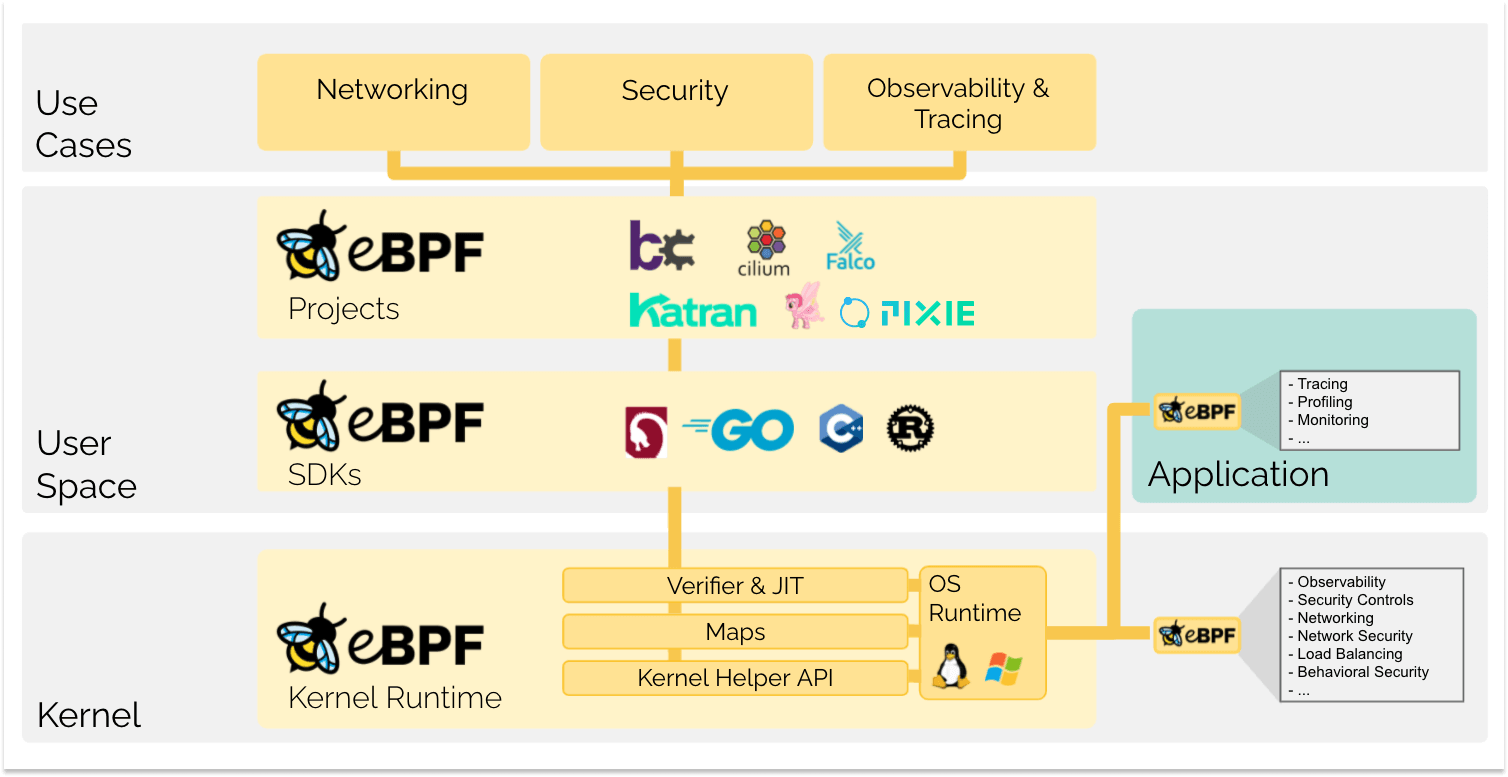
eBPF change complètement la donne. Cette technologie permet aux développeurs d’exécuter des programmes confinés dans le noyau, et ainsi d’ajouter de nouvelles fonctionnalités au système d’exploitation qui tourne sur une machine. Le système d'exploitation garantit alors la sûreté des programmes grâce à un vérificateur, et assure une vitesse d'exécution égale au code natif à l'aide d'un compilateur Just-In-Time (JIT). En conséquence, une vague de projets basés sur eBPF a vu le jour, couvrant un large éventail d’applications, notamment pour des fonctionnalités de réseau, d'observabilité et de sécurité nouvelle génération.
Aujourd'hui, eBPF est largement utilisé pour des usages multiples : fournir une mise en réseau et un équilibrage de charge hautes performances dans les centres de données modernes et les environnements natifs au cloud, visualiser avec précision et à moindre coût les données relatives à la sécurité d’un système, aider les développeurs à tracer les applications, fournir des informations pour le dépannage des problèmes de performances, sécuriser de façon préventive les applications et l'exécution des conteneurs, et bien plus encore. Les possibilités sont infinies et l'innovation que permet eBPF n’en est qu’à ses débuts.
eBPF.io est un lieu où tout le monde peut apprendre et collaborer autour d'eBPF. eBPF est une communauté ouverte où chacun peut participer et partager. Que vous souhaitiez lire une première introduction à eBPF, trouver du matériel de lecture supplémentaire ou faire vos premiers pas pour devenir contributeur sur des projets eBPF majeurs, eBPF.io vous aidera tout au long du chemin.
BPF signifiait à l'origine Berkeley Packet Filter, mais maintenant qu’eBPF (« extended BPF ») peut faire bien plus que filtrer des paquets, l'acronyme n'a plus de sens. eBPF est désormais considéré comme un terme autonome qui ne signifie plus vraiment quelque chose. Dans le code source de Linux, le terme BPF persiste, et dans les outils et la documentation, les termes BPF et eBPF sont généralement utilisés de manière interchangeable. Le BPF d'origine est parfois appelé cBPF (classic BPF) pour le distinguer d’eBPF.
L'abeille est le logo officiel d'eBPF et a été créée par Vadim Shchekoldin. Lors du premier sommet eBPF, un vote a eu lieu et l'abeille a été nommée eBee. (Pour plus de détails sur les utilisations acceptables du logo, consultez les directives de la marque Linux Foundation Brand Guidelines.)
Les chapitres suivants sont une introduction rapide à eBPF. Si vous souhaitez en apprendre plus sur le sujet, consultez le Guide de référence eBPF et XDP. Que vous soyez un développeur cherchant à créer un programme eBPF ou que vous souhaitiez mettre à profit une solution qui utilise eBPF, il est utile de comprendre les concepts et l’architecture de base.
Les programmes eBPF sont pilotés par des événements et sont exécutés lorsque le noyau ou une application passe un certain hook (point d’attache). Les hooks prédéfinis incluent les appels système, l'entrée/sortie de fonctions, les points de trace du noyau, les événements réseau, et d’autres encore.
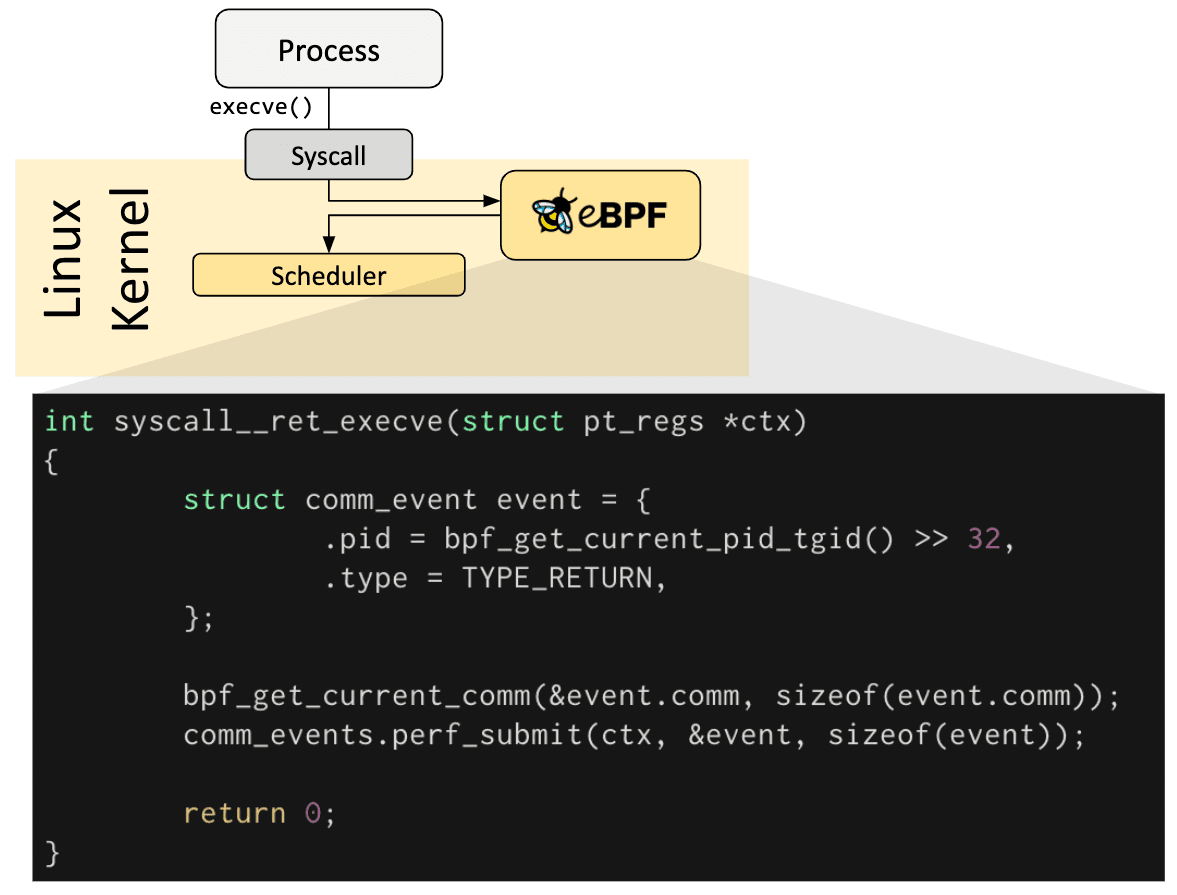
Si un hook prédéfini n'existe pas pour un besoin particulier, il est possible de créer une sonde noyau (kprobe) ou une sonde utilisateur (uprobe) pour attacher des programmes eBPF presque n'importe où dans le noyau ou les applications utilisateur.
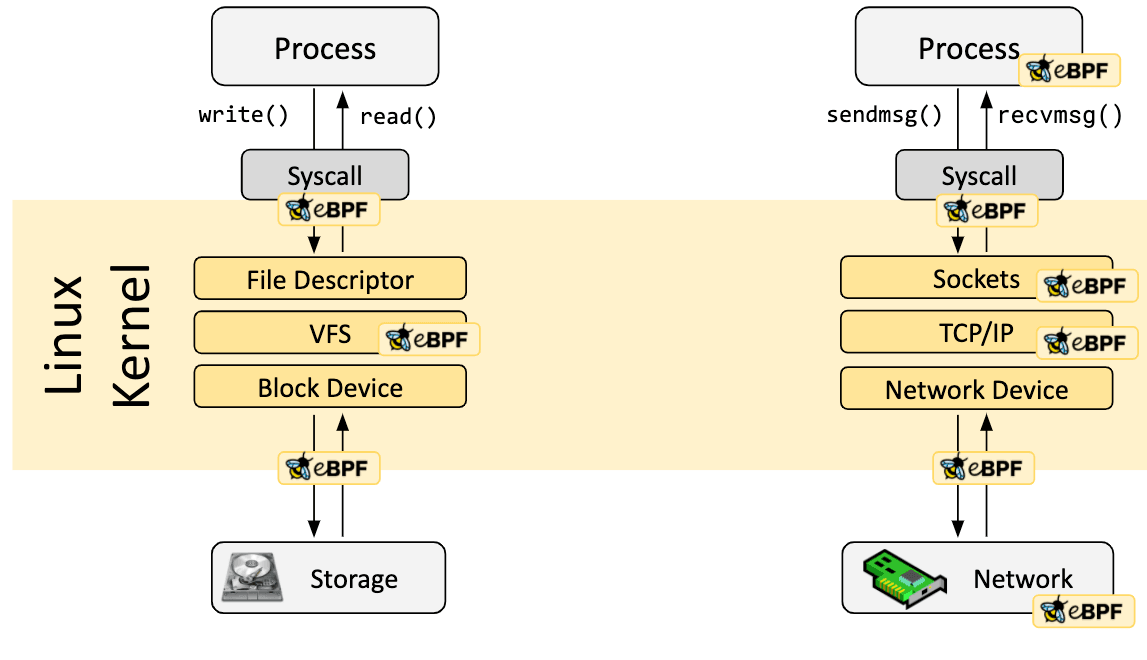
Dans de nombreux scénarios, eBPF n'est utilisé que de manière indirecte via des projets tels que Cilium, bcc ou bpftrace, qui fournissent une abstraction au-dessus d'eBPF et ne nécessitent pas d'écrire directement des programmes. Les utilisateurs spécifient leurs intentions dans un langage haut niveau, et ces projets mettent en œuvre l’implémentation en gérant les programmes eBPF.

S'il n'existe pas d'abstraction pour un usage donné, les programmes doivent être écrits directement. Le noyau Linux s'attend à ce que les programmes eBPF soient chargés sous forme de code machine. Bien qu'il soit possible d'écrire du code machine directement, la pratique de développement la plus courante consiste à utiliser une chaîne de compilation comme LLVM pour transformer du code pseudo-C en code eBPF.
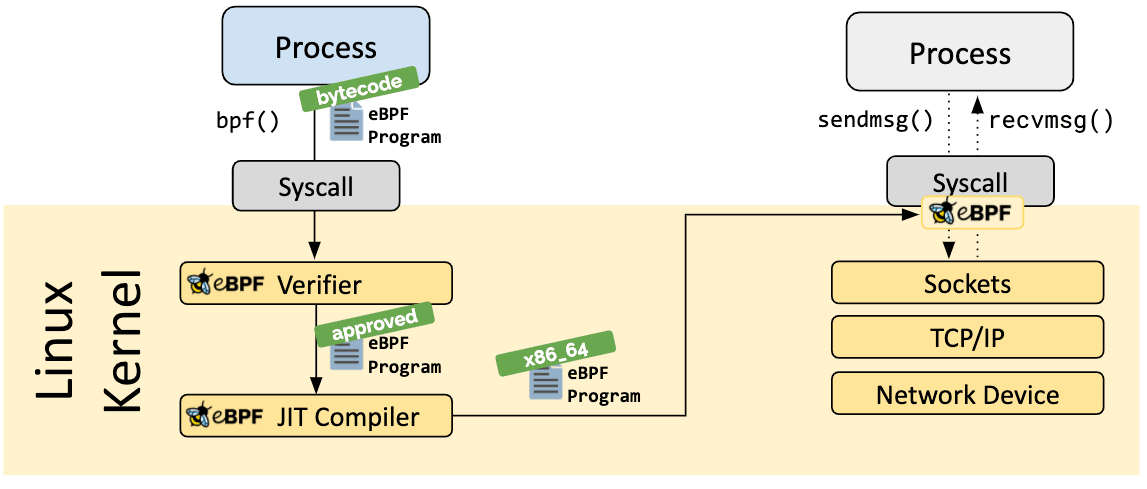
Lorsque le hook souhaité a été identifié, le programme eBPF peut être chargé dans le noyau Linux à l'aide de l'appel système bpf. Cet appel est généralement pris en charge par l'une des bibliothèques eBPF existantes. La section suivante fournit une introduction aux chaînes d'outils disponibles.
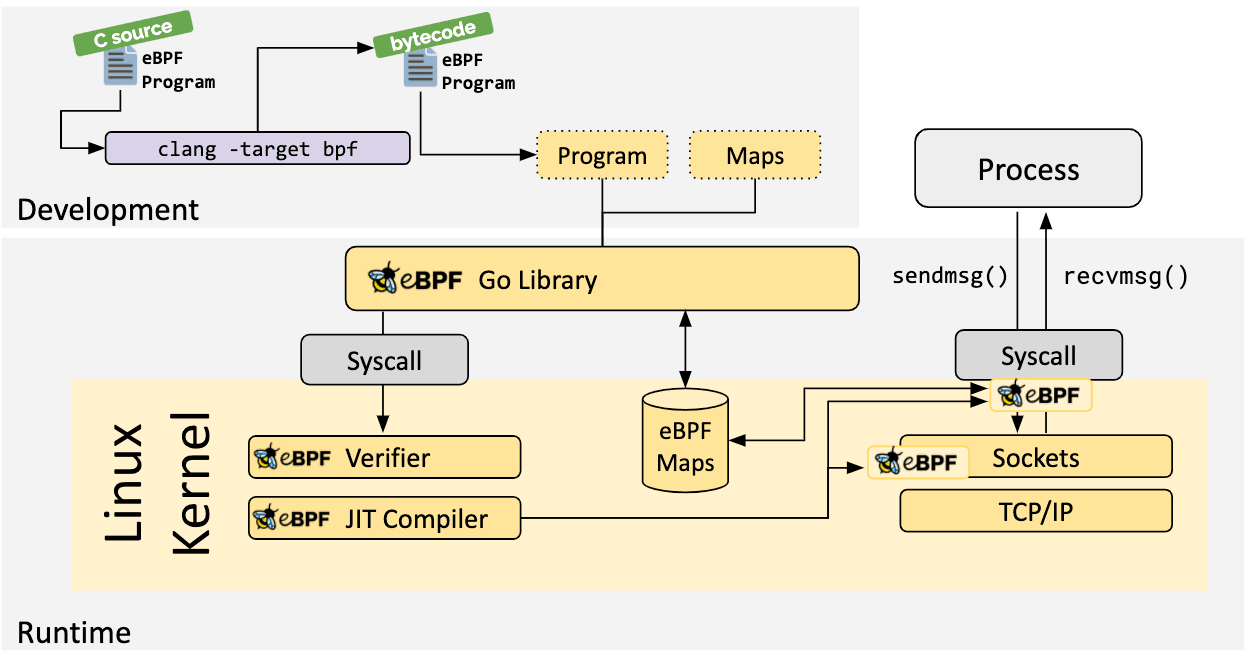
Lorsque le programme est chargé dans le noyau Linux, il passe par deux étapes avant d'être attaché au hook demandé :
L’étape de vérification garantit que le programme eBPF peut être exécuté en toute sûreté. Elle assure que le programme respecte plusieurs contraintes, par exemple :
- Le processus chargeant le programme eBPF détient les privilèges requise. À moins qu’une option dédiée ne soit activée, seuls les processus privilégiés peuvent charger des programmes eBPF.
- Le programme ne plante pas ou n'endommage pas le système.
- Le programme s'exécute toujours jusqu'à la fin (c'est-à-dire que le programme ne reste pas indéfiniment dans une boucle, ce qui empêcherait le système de poursuivre son exécution).
L'étape de compilation Just-in-Time (JIT) traduit le code assembleur générique du programme en instructions spécifiques à la machine pour optimiser la vitesse d'exécution du programme. Cela permet aux programmes eBPF de s'exécuter aussi rapidement que le code compilé nativement dans le noyau ou que le code chargé en tant que module.
Un aspect essentiel des programmes eBPF est la capacité de partager les informations collectées et à stocker un état. À cette fin, les programmes eBPF peuvent tirer parti des maps eBPF pour stocker et récupérer des données dans diverses structures de données. Les maps eBPF sont accessibles depuis les programmes eBPF ainsi que depuis les applications en espace utilisateur, via un appel système.
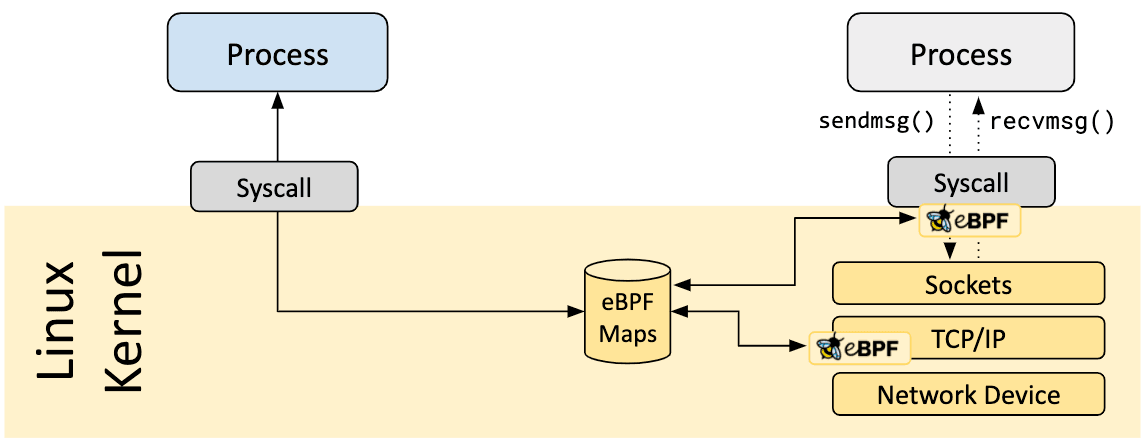
Voici une liste non exhaustive des types de maps prises en charge afin de donner une idée de la diversité des structures de données. Pour certains types de maps, une variante simple (partagée entre les cœurs processeurs) et une variante par processeur sont disponibles.
- Tables de hachage, tableaux
- LRU (Least Recently Used = moins récemment utilisé)
- Tampon circulaire
- Trace de la pile
- LPM (Longest Prefix match = correspondance du préfixe le plus long)
- ...
Les programmes eBPF n’ont pas accès à des fonctions arbitraires du noyau. S’ils l’avaient, ils se retrouveraient liés à une version particulière du noyau, ce qui compliquerait la portabilité des programmes. À la place, le noyau met à disposition des programmes eBPF un certain nombre de fonctions permettant de réaliser des tâches spécifiques, et qui forment une API connue et stable.

L'ensemble de ces fonctions est en constante évolution. Voici quelques exemples de tâches réalisées par les fonctions disponibles :
- Générer des nombres aléatoires
- Obtenir l'heure et la date actuelles
- Accéder aux maps eBPF
- Obtenir le contexte d’un processus ou d’un cgroup
- Manipuler les paquets réseau et la logique de transfert
Les programmes eBPF sont composables avec le concept d'appels final (tail calls) et de fonctions (functions call). Les appels de fonctions permettent de définir et d'appeler des fonctions dans un programme eBPF. Les appels finaux peuvent appeler et exécuter un autre programme eBPF en remplaçant le contexte d'exécution, de la même manière que l'appel système execve() fonctionne pour les processus normaux.
Un grand pouvoir entraîne de grandes responsabilités.
eBPF est une technologie incroyablement puissante et fonctionne désormais au cœur de nombreux composants critiques de l'infrastructure logicielle. Lors du développement d'eBPF et au moment de son inclusion dans le noyau Linux, la sécurité d'eBPF était l'aspect le plus crucial. Cette sécurité est assurée à travers plusieurs couches :
Privilèges requis
À moins qu’une option dédiée ne soit activée, tous les processus qui tentent de charger des programmes eBPF dans le noyau Linux doivent s'exécuter en mode privilégié (administrateur) ou nécessitent la capacité CAP_BPF. Cela signifie que les programmes non approuvés ne peuvent pas charger de programmes eBPF.
Si l’option est activée, les processus non privilégiés peuvent charger certains programmes eBPF avec un ensemble de fonctionnalités réduit et un accès limité au noyau.
Vérificateur
Même si un processus dispose des privilèges requis, tous les programmes passent systématiquement par le vérificateur eBPF. Ce vérificateur eBPF assure la sécurité de ces programmes. Voici quelques exemples des contraintes appliquées :
- Les programmes sont validés pour s'assurer qu'ils sont toujours exécutés jusqu'à la fin, par exemple un programme eBPF ne peut jamais bloquer l’exécution ou rester dans une boucle indéfiniment. Les programmes eBPF peuvent contenir des boucles délimitées, mais le programme n'est accepté que si le vérificateur est en mesure de s'assurer que la sortie de boucle est garantie.
- Les programmes ne peuvent pas utiliser des variables non initialisées ou accéder à de la mémoire en dehors des limites.
- Les programmes doivent respecter les exigences de taille du système. Il n'est pas possible de charger des programmes eBPF arbitrairement volumineux.
- Le programme doit avoir une complexité finie. Le vérificateur évaluera tous les chemins d'exécution possibles et doit être capable de terminer l'analyse dans les limites de la borne de complexité.
Le vérificateur est conçu comme un outil de sureté, vérifiant que les programmes peuvent être exécutés de façon sûre. Ce n'est pas un outil de sécurité inspectant ce que font les programmes.
Durcissement
Une fois la vérification terminée avec succès, le programme eBPF passe par une étape de durcissement plus ou moins accentuée selon que le programme est chargé à partir d'un processus privilégié ou non privilégié. Cette étape comprend les éléments suivants :
- Protection de l'exécution du programme: la mémoire du noyau contenant un programme eBPF est protégée et en lecture seule. Si pour une raison quelconque, qu'il s'agisse d'un bogue du noyau ou d'une manipulation malveillante, une entité tente de modifier le programme eBPF, le noyau plantera au lieu de permettre l’exécution du programme corrompu ou manipulé.
- Atténuation contre Spectre: lorsqu’ils spéculent sur l’exécution des branches, les processeurs peuvent produire des effets secondaires observables qui pourraient être extraits via un canal auxiliaire. Pour ne citer que quelques exemples : les programmes eBPF masquent les accès mémoire afin de rediriger les accès sous instructions transitoires vers des zones contrôlées ; le vérificateur suit également les chemins de programme accessibles uniquement en exécution spéculative et le compilateur JIT émet des Retpolines au cas où les appels finaux ne peuvent pas être convertis en appels directs.
- Masquage des constantes: toutes les constantes du code sont masquées pour empêcher les attaques de type JIT spraying. Cela empêche les attaquants d'injecter du code exécutable sous forme de constantes qui, en présence d'un autre bogue du noyau, pourraient permettre à l’attaquant de sauter dans la section mémoire du programme eBPF pour exécuter du code.
Abstraction du contexte d'exécution
Les programmes eBPF ne peuvent pas accéder directement à une position arbitraire de l’espace mémoire du noyau. Les données et structures de données qui se trouvent en dehors du contexte du programme sont accessibles uniquement via les helpers eBPF. Cela garantit un accès cohérent aux données et restreint tout accès de ce type aux privilèges du programme eBPF Par exemple, un programme eBPF en cours d'exécution est autorisé à modifier les données de certaines structures de données si la modification peut être garantie comme étant sûre. Un programme eBPF ne peut pas modifier aléatoirement des structures de données dans le noyau.
Commençons par une analogie. Vous souvenez-vous de GeoCities ? Il y a 20 ans, les pages web étaient presque exclusivement écrites en langage de balisage statique (HTML). Une page web était essentiellement un document qu’une application (un navigateur) était capable d'afficher. Aujourd'hui, les pages web sont devenues des applications à part entière et la technologie web a remplacé la grande majorité des applications écrites dans des langages compilés. Qu'est-ce qui a permis cette évolution ?
La réponse courte est la programmabilité avec l'introduction de JavaScript. Elle a débloqué une révolution massive qui a transformé les navigateurs, au point qu’ils se rapprochent désormais de systèmes d'exploitation presque indépendants.
Pourquoi l'évolution s'est-elle produite ? Les programmeurs n'étaient plus contraints par les versions particulières du navigateur qu’exécutaient les utilisateurs. Au lieu de convaincre les organismes de normalisation qu'une nouvelle balise HTML était requise, ces programmeurs avaient à disposition les blocs de construction nécessaires pour leur projet, ce qui a dissocié le rythme d'innovation du navigateur de celui de l'application qui tourne dessus. Bien sûr, il s’agit d’un résumé simpliste, car HTML a évolué au fil du temps et a contribué à ces changements, mais la seule évolution du langage HTML n'aurait pas été suffisante.
Avant de prendre cet exemple et de l'appliquer à eBPF, examinons les clés du succès de JavaScript :
- Sécurité: un code non fiable s'exécute dans le navigateur de l'utilisateur. Ce problème a été résolu en plaçant les programmes JavaScript en bac à sable et en supprimant l'accès aux données du navigateur.
- Livraison continue: l'évolution de la logique du programme doit être possible sans nécessiter la livraison constante de nouvelles versions de navigateur. Pour ce faire, les blocs de construction permettant de bâtir la logique de différents projets sont fournis par le navigateur.
- Performance: La programmabilité ne doit pas se faire au détriment des performances. L'introduction d'un compilateur Just-In-Time (JIT) a permis de conserver une grande vitesse d’exécution. Pour tous les éléments cités se trouve un équivalent du côté d’eBPF, pour les mêmes raisons.
Revenons maintenant à eBPF. Afin de comprendre l'impact de la programmabilité d'eBPF sur le noyau Linux, il faut une vision de haut niveau de l'architecture du noyau Linux et de la façon dont il interagit avec les applications et le matériel.
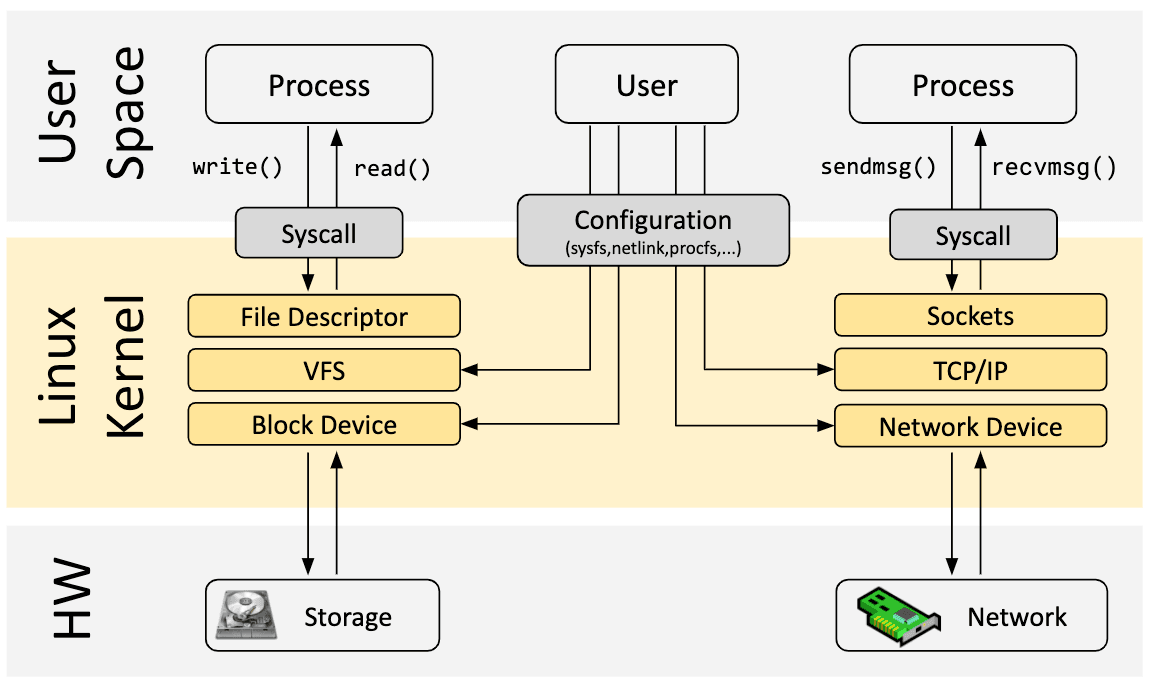
L'objectif principal du noyau Linux est d'abstraire le matériel, réel ou virtuel, et de fournir une API cohérente (appels système) permettant aux applications d'exécuter et de partager les ressources. Pour ce faire, un large ensemble de sous-systèmes et d’abstractions est maintenu pour répartir ces responsabilités. Chaque sous-système offre généralement un certain niveau de configuration pour tenir compte des différents besoins des utilisateurs. Mais si le comportement souhaité par un utilisateur ne peut pas être configuré, alors un changement dans le noyau est requis, ce qui, historiquement, laissait le choix entre deux options :
Support natif
- Modifier le code source du noyau et convaincre la communauté du noyau Linux que la modification est nécessaire.
- Attendre plusieurs années pour que la nouvelle version du noyau soit distribuée.
Module noyau
- Écrire un module noyau
- À corriger régulièrement, car chaque version du noyau peut le casser
- Risque de corrompre le noyau Linux en raison du manque de contraintes pour la sécurité
eBPF offre une nouvelle option qui permet de reprogrammer le comportement du noyau Linux sans nécessiter de modifications du code source du noyau ni de chargement d'un module. À bien des égards, cela ressemble beaucoup à la manière dont JavaScript et d'autres langages de script ont débloqué l'évolution de systèmes qui étaient devenus difficiles ou coûteux à modifier.
Plusieurs chaînes d'outils existent pour aider au développement et à la gestion des programmes eBPF. Tous répondent aux différents besoins des utilisateurs :
bcc
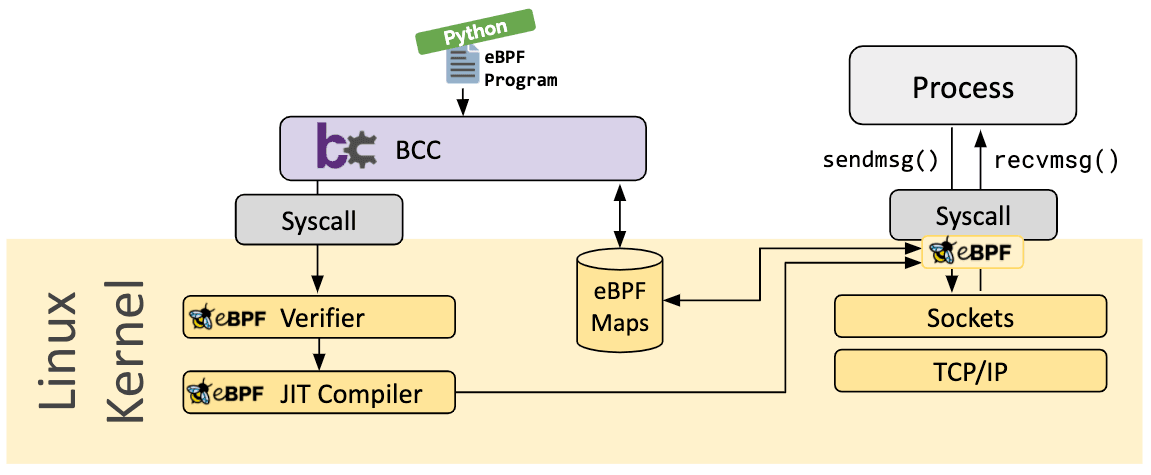
BCC est un projet qui permet aux utilisateurs d'écrire des programmes python avec des programmes eBPF intégrés à l'intérieur. BCC cible principalement les cas qui impliquent le profilage/traçage d'applications et de systèmes. Un programme eBPF est utilisé pour collecter des statistiques ou générer des événements, tandis qu’un collecteur en espace utilisateur récupère les données et les affiche sous une forme lisible par l’utilisateur. L'exécution du programme Python génère le code assembleur eBPF et le charge dans le noyau.
bpftrace
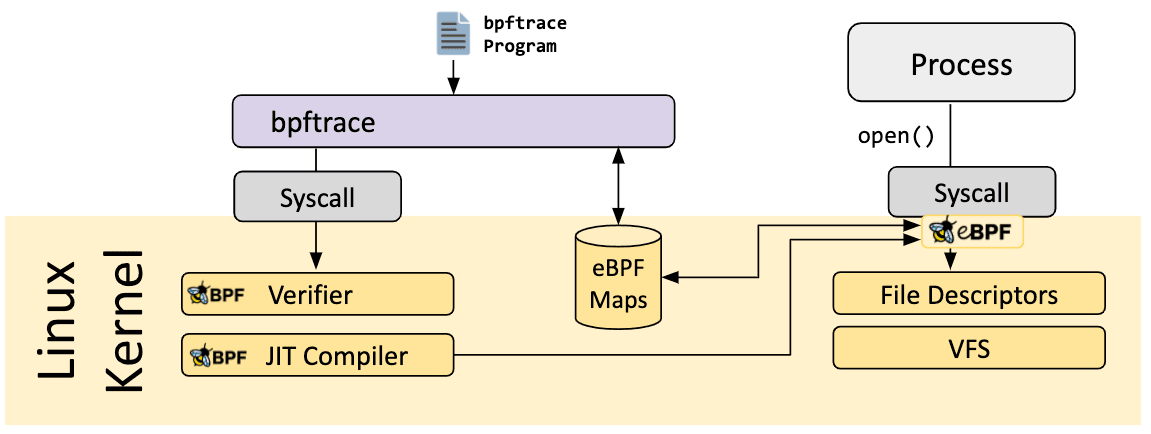
bpftrace est un langage de traçage de haut niveau pour eBPF sur Linux. bpftrace utilise LLVM comme backend pour compiler des scripts en code assembleur eBPF et utilise BCC gérer les programmes eBPF. Le projet utilise plusieurs des capacités de traçage Linux existantes : traçage dynamique du noyau (kprobes), traçage dynamique au niveau de l'utilisateur (uprobes) et points de trace. Le langage bpftrace est inspiré des traceurs awk, C et de prédécesseurs tels que DTrace et SystemTap.
Bibliothèque eBPF Go
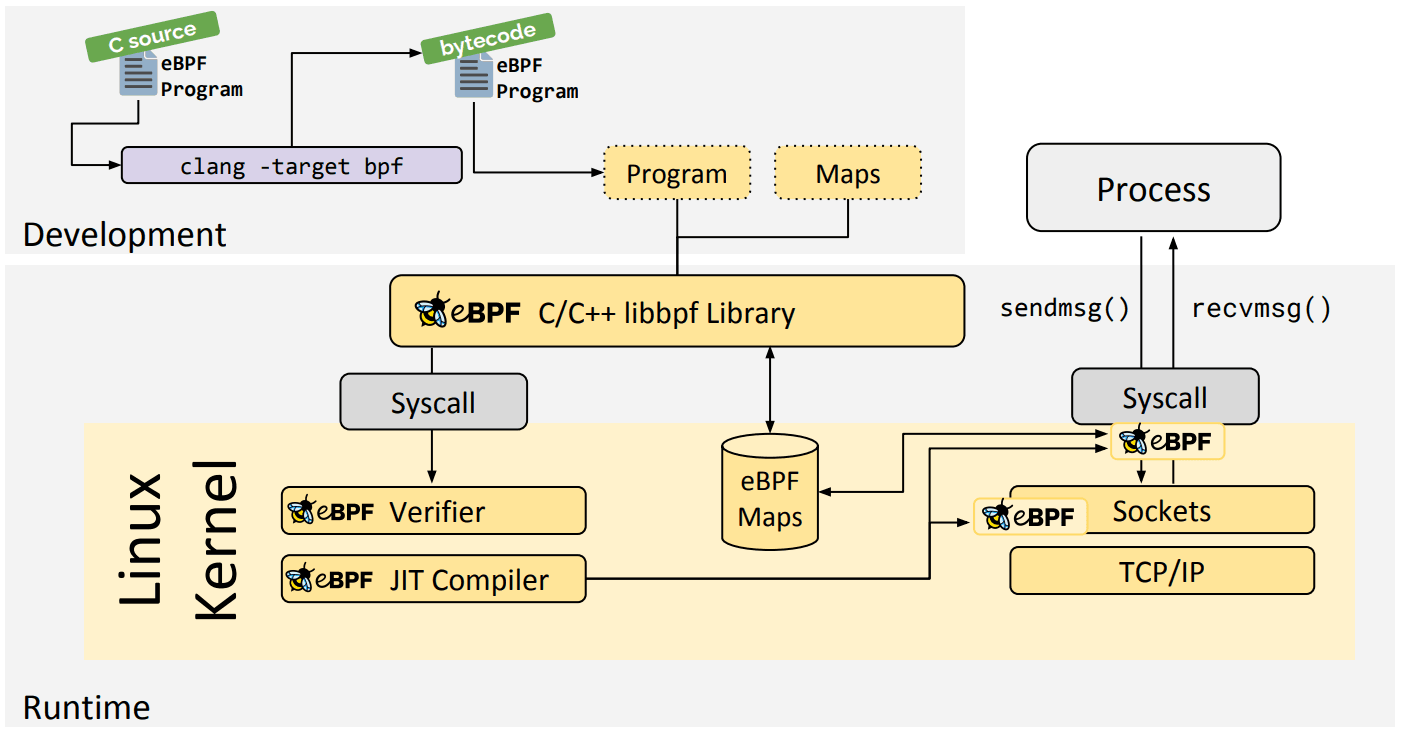
eBPF Go est une bibliothèque eBPF générique qui dissocie l’'accès au bytecode eBPF du chargement et de la gestion des programmes eBPF. Les programmes eBPF sont généralement créés à l’aide d’un langage haut niveau, puis en utilisant le compilateur clang/LLVM pour compiler en code machine eBPF.
Bibliothèque C/C++ libbpf
Libbpf est une bibliothèque eBPF générique en C/C++ qui permet de manipuler les programmes contenus dans des fichiers objets eBPF générés à partir du compilateur clang/LLVM. Elle dissocie le chargement des programmes dans le noyau de leur attache. Elle propose une abstraction pour l'appel système bpf et fournit des API faciles à utiliser par les applications.
Si vous souhaitez en savoir plus sur eBPF, continuez votre lecture à l’aide de ces documents :
- BPF & XDP Reference Guide, Cilium Documentation, Aug 2020
- BPF Documentation, BPF Documentation in the Linux Kernel
- BPF Design Q&A, FAQ for kernel-related eBPF questions
- Learn eBPF Tracing: Tutorial and Examples, Brendan Gregg's Blog, Jan 2019
- XDP Hands-On Tutorials, Various authors, 2019
- BCC, libbpf and BPF CO-RE Tutorials, Facebook's BPF Blog, 2020
Generic
- eBPF and Kubernetes: Little Helper Minions for Scaling Microservices (Slides), Daniel Borkmann, KubeCon EU, Aug 2020
- eBPF - Rethinking the Linux Kernel (Slides), Thomas Graf, QCon London, April 2020
- BPF as a revolutionary technology for the container landscape (Slides), Daniel Borkmann, FOSDEM, Feb 2020
- BPF at Facebook, Alexei Starovoitov, Performance Summit, Dec 2019
- BPF: A New Type of Software (Slides), Brendan Gregg, Ubuntu Masters, Oct 2019
- The ubiquity but also the necessity of eBPF as a technology, David S. Miller, Kernel Recipes, Oct 2019
Deep Dives
- BPF and Spectre: Mitigating transient execution attacks (Slides) , Daniel Borkmann, eBPF Summit, Aug 2021
- BPF Internals (Slides), Brendan Gregg, USENIX LISA, Jun 2021
Cilium
- Advanced BPF Kernel Features for the Container Age (Slides), Daniel Borkmann, FOSDEM, Feb 2021
- Kubernetes Service Load-Balancing at Scale with BPF & XDP (Slides), Daniel Borkmann & Martynas Pumputis, Linux Plumbers, Aug 2020
- Liberating Kubernetes from kube-proxy and iptables (Slides), Martynas Pumputis, KubeCon US 2019
- Understanding and Troubleshooting the eBPF Datapath in Cilium (Slides), Nathan Sweet, KubeCon US 2019
- Transparent Chaos Testing with Envoy, Cilium and BPF (Slides), Thomas Graf, KubeCon EU 2019
- Cilium - Bringing the BPF Revolution to Kubernetes Networking and Security (Slides), Thomas Graf, All Systems Go!, Berlin, Sep 2018
- How to Make Linux Microservice-Aware with eBPF (Slides), Thomas Graf, QCon San Francisco, 2018
- Accelerating Envoy with the Linux Kernel, Thomas Graf, KubeCon EU 2018
- Cilium - Network and Application Security with BPF and XDP (Slides), Thomas Graf, DockerCon Austin, Apr 2017
Hubble
- Hubble - eBPF Based Observability for Kubernetes, Sebastian Wicki, KubeCon EU, Aug 2020
- Learning eBPF, Liz Rice, O'Reilly, 2023
- Security Observability with eBPF, Natália Réka Ivánkó and Jed Salazar, O'Reilly, 2022
- What is eBPF?, Liz Rice, O'Reilly, 2022
- Systems Performance: Enterprise and the Cloud, 2nd Edition, Brendan Gregg, Addison-Wesley Professional Computing Series, 2020
- BPF Performance Tools, Brendan Gregg, Addison-Wesley Professional Computing Series, Dec 2019
- Linux Observability with BPF, David Calavera, Lorenzo Fontana, O'Reilly, Nov 2019
- BPF for security - and chaos - in Kubernetes, Sean Kerner, LWN, Jun 2019
- Linux Technology for the New Year: eBPF, Joab Jackson, Dec 2018
- A thorough introduction to eBPF, Matt Fleming, LWN, Dec 2017
- Cilium, BPF and XDP, Google Open Source Blog, Nov 2016
- Archive of various articles on BPF, LWN, since Apr 2011
- Various articles on BPF by Cloudflare, Cloudflare, since March 2018
- Various articles on BPF by Facebook, Facebook, since August 2018